In de klassieke wetenschappelijk informatiepyramide staat de zogenaamde systematic review bovenaan, vooral de biomedische wetenschappen. Die publicaties zijn gebaseerd op inzichten samengebracht uit grotere hoeveelheden gepubliceerd onderzoek. Het literatuuronderzoek voor zo’n systematic review vereist dan ook dan een systematische, transparante aanpak. In een systematic review wordt getracht om een onderzoeksvraag te beantwoorden door te kijken naar de resultaten van bestaand onderzoek. Om tot goede conclusies te komen is het daarbij van het grootste belang om geen relevant onderzoek te missen. De zogenaamde recall heeft prioriteit. Dus bij het zoeken moeten alle mogelijke varianten van zoektermen worden meegenomen. Dat leidt tot vaak zeer lange Booleaanse zoekvragen die op de zoekmachines en wetenschappelijke databases worden losgelaten. En die zoekvragen worden nog langer omdat niet-relevante contexten waarin die zoektermen voorkomen moeten worden uitgesloten. Het zoeken is bij systematic reviews echt een wezenlijk onderdeel dat gedocumenteerd wordt en waarover ook gerapporteerd wordt.
Systematic reviews worden steeds vaker gedaan en zijn ook in opkomst in vakgebieden waar ze eerst zeldzaam waren. Complexiteit van vraagstukken is vaak zo groot dat alleen een systematic review die kan vangen. En in toepassingen en beleid wil men niet graag varen op resultaten van slechts één of enkele onderzoeken. Het percentage artikelen dat rapporteert over een systematic review is gestegen van ongeveer 3 promille in 2011 naar 11 promille in 2021 uitgaande van een grove check op artikelen met “systematic review” in de titel of abstract in de zoekmachine Dimensions. Ook zie je dat ook in onderzoek dat niet tot doel heeft een systematic review te doen steeds vaker wel een vergelijkbare systematische zoekaanpak wordt gebruikt.
Interessant is dat ik steeds vaker de vraag krijg of een dergelijke grondige aanpak ook toegepast kan worden op webbronnen, met Google of andere webzoekmachines. En dan wordt het interessant. Want zowel de bronnen zelf als de tools om te zoeken zijn minder gestandaardiseerd en gecontroleerd. Er zijn weliswaar veel dingen die je kunt doen om je zoekactie zo goed mogelijk te maken, qua recall en precision, maar hoe zoekmachines precies met je zoekvraag omgaan blijft een beetje koffiedik. Hun algoritmes zijn bedrijfsgeheim, hun ranking lastig te beïnvloeden of uit te schakelen. De vraag is hoe ver je kunt komen met proberen een systematische, gecontroleerde en transparante webzoekactie te doen. Als je daarbij alles uit de kast haalt (zie de gelinkte figuur voor alle details van het proces), kun je dan in de buurt komen van de mate van controle die je hebt bij zoekacties voor systematic reviews gebaseerd op wetenschappelijke artikelen? Je kunt er heel veel tijd steken, door geavanceerde zoekopties te gebruiken, personalisatie zoveel mogelijk uit te schakelen, deels meer gecontroleerde databases te gebruiken (bijvoorbeeld Policy Commons voor rapporten), Google’s programmable search te gebruiken, meertalig te zoeken en nog veel meer. Die stappen en acties zijn wel erg divers, contextafhankelijk en hebben vaak een lastig te evalueren effect. Het eindresultaat zal waarschijnlijk dan ook nog steeds met veel onzekerheden omgeven zijn.
We nemen niettemin in een workshop tijdens de komende VOGIN-IP lezing de proef op de som. Want er zijn wel degelijk vragen waarbij inzichten uit niet-wetenschappelijke bronnen van groot belang zijn. Die kunnen we niet links laten liggen omdat het minder eenduidig ontsloten is. Het is aan ons om het gereedschap dat we gebruiken telkens weer aan te scherpen zodat we ook veeleisende vragen aankunnen.
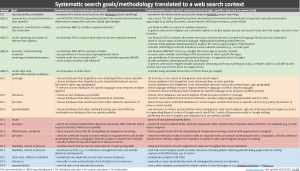
De volledige procedure en lijst van mogelijke acties is beschikbaar op: https://tinyurl.com/systematicwebsearch
Jeroen Bosman